Organizing Serverless Projects
Once your serverless projects start to grow, you are faced with some choices on how to organize your growing projects. In this chapter we’ll examine some of the most common ways to structure your projects at a services and application (multiple services) level.
First let’s start by quickly looking at the common terms used when talking about Serverless Framework projects.
-
Service
A service is what you might call a Serverless project. It has a single
serverless.ymlfile driving it. -
Application
An application or app is a collection of multiple services.
Now let’s look at the most common pattern for organizing serverless projects with our example repos.
An example
Our extended notes app has two API services, each has their own well defined business logic:
- notes-api service: Handles managing the notes.
- billing-api service: Handles making a purchase.
And your app also has a job service:
- notify-job service: Sends you a text message after a user successfully makes a purchase.
The infrastructure is created by the following services:
- auth service: Defines a Cognito User and Identity pool used to store user data.
- database service: Defines a DynamoDB table called
notesused to store notes data. - uploads service: Defines an S3 bucket used to store note images.
Microservices + Monorepo
Monorepo, as the term suggests is the idea of a single repository. This means that your entire application and all its services are in a single repository.
The microservice pattern on the other hand is a concept of keeping each of your services modular and lightweight. So for example; if your app allows users to create notes and make purchase; you could have a service that deals with notes and one that deals with buying.
The directory structure of your entire application under the microservice + monorepo pattern would look something like this.
|- services/
|--- auth/
|--- billing-api/
|--- database/
|--- notes-api/
|--- notify-job/
|--- uploads/
|- libs/
|- package.json
A couple of things to notice here:
- We are going over a Node.js project here but this pattern applies to other languages as well.
- The
services/dir at the root is made up of a collection of services. Where a service contains a singleserverless.ymlfile. - Each service deals with a relatively small and self-contained function. So for example, the
notes-apiservice deals with everything from creating to deleting notes. Of course, the degree to which you want to separate your application is entirely up to you. - The
package.json(and thenode_modules/dir) are at the root of the repo. However, it is fairly common to have a separatepackage.jsoninside each service directory. - The
libs/dir is just to illustrate that any common code that might be used across all services can be placed in here. - To deploy this application you are going to need to run
serverless deployseparately in each of the services. - Environments (or stages) need to be co-ordinated across all the different services. So if your team is using a
dev,staging, andprodenvironment, then you are going to need to define the specifics of this in each of the services.
Advantages of Monorepo
The microservice + monorepo pattern has grown in popularity for a couple of reasons:
-
Lambda functions are a natural fit for a microservice based architecture. This is due to a few of reasons. Firstly, the performance of Lambda functions is related to the size of the function. Secondly, debugging a Lambda function that deals with a specific event is much easier. Finally, it is just easier to conceptually relate a Lambda function with a single event.
-
The easiest way to share code between services is by having them all together in a single repository. Even though your services end up dealing with separate portions of your app, they still might need to share some code between them. Say for example; you have some code that formats your requests and responses in your Lambda functions. This would ideally be used across the board and it would not make sense to replicate this code in all the services.
Disadvantages of Monorepo
Before we go through alternative patterns, let’s quickly look at the drawbacks of the microservice + monorepo pattern.
- Microservices can grow out of control and each added service increases the complexity of your application.
- This also means that you can end up with hundreds of Lambda functions.
- Managing deployments for all these services and functions can get complicated.
Most of the issues described above start to appear when your application begins to grow. However, there are services that help you deal with some these issues. Services like IOpipe, Epsagon, and Dashbird help you with observability of your Lambda functions. And our own Seed helps you with managing deployments and environments of monorepo Serverless Framework applications.
Now let’s look at some alternative approaches.
Multi-Repo
The obvious counterpart to the monorepo pattern is the multi-repo approach. In this pattern each of your repositories has a single Serverless Framework project.
A couple of things to watch out for with the multi-repo pattern.
-
Code sharing across repos can be tricky since your application is spread across multiple repos. There are a couple of ways to deal with this. In the case of Node you can use private NPM modules. Or you can find ways to link the common shared library of code to each of the repos. In both of these cases your deployment process needs to accommodate for the shared code.
-
Due to the friction involved in code sharing, we typically see each service (or repo) grow in the number of Lambda functions. This can cause you to hit the CloudFormation resource limit and get a deployment error that looks like:
Error -------------------------------------------------- The CloudFormation template is invalid: Template format error: Number of resources, 201, is greater than maximum allowed, 200
Even with the disadvantages the multi-repo pattern does have its place. We have come across cases where some infrastructure related pieces (setting up DynamoDB, Cognito, etc) is done in a service that is placed in a separate repo. And since this typically doesn’t need a lot of code or even share anything with the rest of your application, it can live on its own. So in effect you can run a multi-repo setup where the standalone repos are for your infrastructure and your API endpoints live in a microservice + monorepo setup.
Finally, it’s worth looking at the less common monolith pattern.
Monolith
The monolith pattern involves taking advantage of API Gateway’s {proxy+} and ANY method to route all the requests to a single Lambda function. In this Lambda function you can potentially run an application server like Express. So as an example, all the API requests below would be handled by the same Lambda function.
GET https://api.example.com/notes
GET https://api.example.com/notes/{id}
POST https://api.example.com/notes
PUT https://api.example.com/notes/{id}
DELETE https://api.example.com/notes/{id}
POST https://api.example.com/billing
And the specific section in your serverless.yml might look like the following:
handler: app.main
events:
- http:
method: any
path: /{proxy+}
Where the main function in your app.js is responsible for parsing the routes and figuring out the HTTP methods to do the specific action necessary.
The biggest drawback here is that the size of your functions keeps growing. And this can affect the performance of your functions. It also makes it harder to debug your Lambda functions.
A practical approach
It’s not the goal of this section to evaluate which setup is better. Instead, I want to layout what we think is a good setup and one that has worked out for most teams we work with. We are taking a middle ground approach and creating two repositories:
In serverless-stack-demo-ext-resources, you have:
/
services/
auth/
database/
uploads/
And in serverless-stack-demo-ext-api, you have:
/
libs/
services/
notes-api/
billing-api/
notify-job/
Why? Most of the code changes are going to happen in the serverless-stack-demo-ext-api repo. When your team is making rapid changes, you are likely to have many feature branches, bug fixes, and pull requests. A bonus with serverless is that you can spin up new environments at zero cost (you only pay for usage, not for provisioning resources). For example, a team can have dozens of ephemeral stages such as: prod, staging, dev, feature-x, feature-y, feature-z, bugfix-x, bugfix-y, pr-128, pr-132, etc. This ensures each change is tested on real infrastructure before being promoted to production.
On the other hand, changes are going to happen less frequently in the serverless-stack-demo-ext-resources repo. And most likely you don’t need a complete set of standalone DynamoDB tables for each feature branch. In fact, a team can have three stages such as: prod, staging, and dev. And the feature/bugfix/pr stages of the serverless-stack-demo-ext-api can all connect to the dev stage of the serverless-stack-demo-ext-resources.
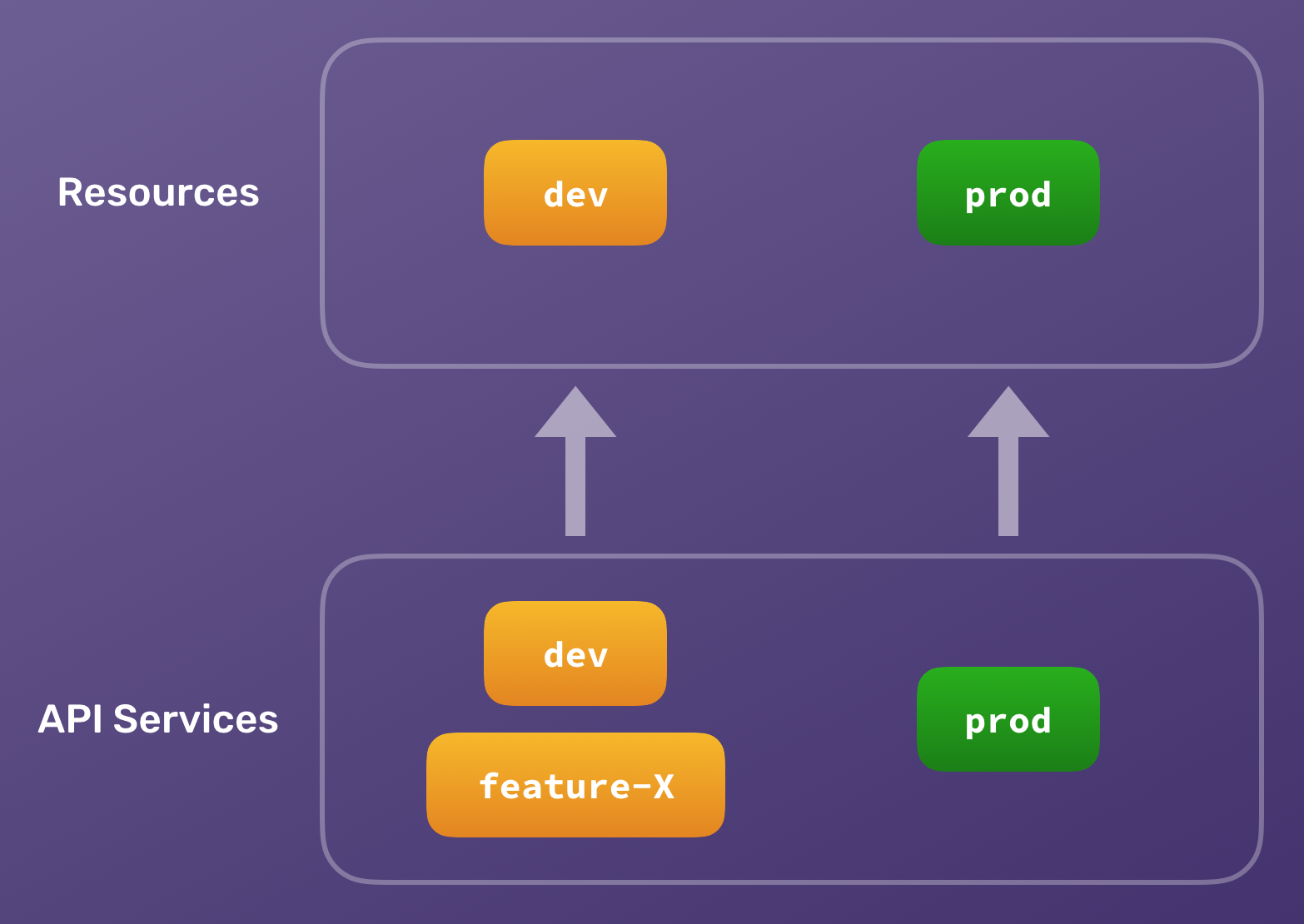
So if you have a service that doesn’t make sense to replicate in an ephemeral environment, we would suggest moving it to the repo with all the infrastructure services. This is what we have seen most teams do. And this setup scales well as your project and team grows.
Now that we have figured out how to organize our application into repos, let’s look at how we split our app into the various services. We’ll start with creating a separate service for our DynamoDB tables.
For help and discussion
Comments on this chapterIf you liked this post, please subscribe to our newsletter, give us a star on GitHub, and follow us on Twitter.
Brought to you by
